INHALTSVERZEICHNIS
B.
Lösungsansätze: NiagaraCQ und XFilter.
I.1. Niagara
Project / NiagaraCQ
II.
Architektur, Profildefinition, effektives Matching
II.1.3. Ansatz zum effizienten Matching
II.2.3. Ansatz zum effizienten Matching
C. Vergleich
der Lösungsansätze
I.
Ausdrucksfähigkeit der Profildefinitionssprachen
III. Ansätze
zum effizienten Matching
Das Thema der vorliegenden Arbeit sind effiziente Verfahren zum Matching von strukturierten Anfragen gegen XML-Dokumente. Als anwendungsorientierter Hintergrund stellt sich die Frage, wie für viele Nutzer jeweils individuell relevante Informationen aus einer großen Anzahl von eingehenden Informationen extrahiert werden können. Diese Fragestellung entspricht dem Anwendungsgebiet von Benachrichtigungssystemen, weshalb zur Untersuchung des Themas die entsprechenden Konzeptionen zweier XML-basierter Benachrichtigungssysteme – NiagaraCQ und XFilter – herangezogen und bezüglich der Effizienz verglichen werden.
Um diesem Vorhaben nachgehen zu können, müssen zunächst einige grundlegende Konzepte der beiden Benachrichtigungssysteme erörtert und die bei der Realisierung jeweils verwandten Technologien und Konzepte erläutert werden. Auf dieser Grundlage kann dann ein Vergleich bezüglich der Effizienz unter verschiedenen Aspekten vorgenommen werden.
Daher ergibt sich folgende Gliederung der Arbeit zur Erfassung des Themas:
Die Erörterung grundlegender Konzepte in Abschnitt A dient dem Verständnis des Anwendungsgebietes der beiden untersuchten Systeme. Einführend werden dabei die grundlegenden Anforderungen sowie die allgemeine Architektur von Benachrichtigungssystemen betrachtet. Der zweite relevante Aspekt ist das technische Konzept zur Realisierung von Benachrichtigungssystemen: hierzu wird das den beiden Systemen zugrundeliegende Konzept der Continuous Queries vorstellt. Als nächstes stellt sich die Frage der Motivation zum Einsatz von XML als Datenformat. Der letzte Aspekt der grundlegenden Konzepte ist die Skalierbarkeit, an die auf Grund des Einsatzgebietes der Systeme im Umfeld des Internet hohe Anforderungen gestellt werden.
Abschnitt B erläutert die Realisierungen der beiden Benachrichtigungssysteme: Da die Systeme beide im Zusammenhang größerer Projekte entstanden sind, werden zunächst die Zielsetzungen dieser Projekte fokussiert, um die grundsätzlich unterschiedliche Herangehensweise der beiden Systeme an die Problemstellung zu verdeutlichen. Dann wird die Umsetzung der Systeme jeweils bezüglich folgender Aspekte beschrieben: Erstens die technische Architektur, zweitens die verwandte Profildefinitionssprache und drittens der jeweilige Ansatz zum effizienten Matchen.
Aufbauend auf den Erläuterungen aus Abschnitt B werden diese Ansätze in Abschnitt C bezüglich der Effizienz verglichen. Auf Grund der herausgearbeiteten Konzepte der beiden Systeme ergeben sich für diesen Vergleich drei Aspekte: erstens die Ausdrucksfähigkeit der verwandten Profildefinitionssprachen, zweitens der Vergleich des erreichten Skalierbarkeitsgrades durch die Realisierungen und drittens die Unterschiede der gewählten Ansätze zum effizienten Matching.
Zum Schluss werden die Ergebnisse der Ausführungen zusammengefasst und
eine Bewertung der Effizienz der Systeme vorgenommen.
In diesem Abschnitt werden einige für das Anwendungsgebiet der zu vergleichenden Systeme relevante Konzepte erläutert, wodurch eine einführende Verständnis-grundlage geschaffen werden soll.
Der nutzerorientierte Zweck eines Benachrichtigungssystems ist, wie oben erwähnt, die Extraktion von individuell relevanten Informationen aus einer großen Menge von Informationen. Dabei definiert der Nutzer eines solchen Systems ein Profil in Form einer Anfrage, wodurch die gewünschten Informationen aus den vorhandenen Datenquellen selektiert und in geeigneter Form an den Nutzer weitergeleitet werden. Die Funktionalität als Benachrichtigungssystem wird dadurch erreicht, dass die Profile als persistente Anfragen im System verbleiben und die Datenquellen bezüglich Änderungen überwacht werden: tritt eine Änderung ein, so wird die Profilanfrage automatisch erneut ausgeführt und der Profilinhaber so über neue, für sein Interessensgebiet relevante Informationen benachrichtigt. Somit ergibt sich die Möglichkeit, mehrere Nutzer jeweils über den aktuellen Stand ihrer individuellen Interessensgebiete mittels eines Systems zu informieren (vgl. XFilter, S.2).
Um den Nutzern des Benachrichtigungssystems eine hohe funktionale Qualität zu bieten, ergeben sich drei wesentliche Anforderungen: erstens die Möglichkeit zur Definition aussagekräftiger Anfragen durch die Unterstützung einer entsprechenden Anfragesprache, zweitens eine hochgradige Skalierbarkeit (s.u.) und drittens die Referenzierung eines möglichst großen und aktualisierbaren Datenbestandes, um ein möglichst umfassendes Informationsangebot liefern zu können (vgl. Hinze, S. 3 f).
Die allgemeine Architektur von Benachrichtigungssystemen besteht aus im wesentlichen aus vier Komponenten: Ein Invoker organisiert die Datenquellen, während ein Observer Änderungen an den Datenquellen registriert und Meldungen über entsprechende Events an die Filterkomponente weiterleitet. Diese vergleicht die Events mit den vorhandenen Profilen. Wird ein Profil als passend zu den neuen Informationen ermittelt, so wird eine entsprechende Aktionen der Benachrichtigungs-komponente ausgelöst (vgl. Hinze, S. 5). Auf Grund der hier bearbeiteten Fragestellung stellt die Betrachtung des Zusammenspiels des Observers und der Filterkomponente den Schwerpunkt dieser Arbeit dar.
Das technische Konzept zur Umsetzung von Profilen als persistente Anfragen wird als Continuous Queries (CQs) bezeichnet: dabei werden Anfragen an das System nach ihrer Ausführung nicht aus dem System entfernt, sondern bleiben bestehen und können automatisch wieder ausgeführt werden. Somit kann ein Profilinhaber sein Interessensgebiet einmal definieren und wird – solange das Profil besteht – bei relevanten Änderungen immer benachrichtigt, so dass die oben beschriebene Funktionalität eines Benachrichtigungssystems gegeben ist. Dieses Konzept stammt aus der Datenbankforschung Anfang der 90er Jahre (vgl. NiagaraCQ, Chap. 6).
Für das hier besprochene Anwendungsgebiet sind zwei Arten von CQs zu unterscheiden: Einerseits kann ein Profil mittels einer Timer-Based CQ Änderungen an Datenquellen innerhalb eines bestimmten Zeitintervalls überwachen (eine Benachrichtigung erfolgt auch, wenn keine Änderungen vorliegen), andererseits kann ein Profil die unverzügliche Benachrichtigung bei einer relevanten Datenänderung mittels einer Change-Based CQ definieren (vgl. NiagaraCQ, Chap. 3.6).
III. Einsatz von XML
Die Bezeichnung der beiden Systeme als XML-basierte Benachrichtigungssysteme bezieht sich darauf, dass beide Systeme ausschließlich in XML vorliegende Informationen verarbeiten. Daraus ergibt sich natürlich die Frage, wieso genau dieses Datenformat gewählt wurde.
Dazu sind zunächst die Konzept der eXtensible Markup Language und die daraus resultierende Einsetzbarkeit in verschiedenen Gebieten zu betrachten. Auf Grund des einfachen, semistrukturellen Aufbaus ergeben sich für die Datenverarbeitung sehr nützliche Eigenschaften von XML-Dokumenten. Denn ein XML-Element enthält gleichzeitig drei Arten von Informationen: erstens die inhaltliche Beschreibung durch den Elementnamen, zweitens Zuordnungsinformationen durch Elementattribute und drittens die eigentlichen Daten als Elementinhalt. Durch diese Selbstbeschreibung sind alle Strukturinformationen im Dokument selber impliziert.
Die Vorteile dieser Eigenschaft werden bei der Betrachtung des Erstellungsprozesses eines XML-Dokuments deutlich: je nach Anwenderbedarf kann der logische und inhaltliche Aufbau des Dokumentes ohne Beachtung technischer Restriktionen definiert werden, so dass Informationen aus verschiedenen Anwendungsgebieten in XML erfasst werden können. Weiterhin kann die Zugehörigkeit eines XML-Dokuments zu einer anwenderdefinierten Struktur durch Überprüfung der Wohlgeformtheit und der Validität bezüglich einer DTD (Document Type Definition) oder eines XML-Schemas nachgeprüft werden (s. XML).
Zur Weiterverarbeitung in verschiedenen Umgebungen stehen Werkzeuge wie XSL, XPointer sowie Anfrage- / Adressierungssprachen zum Transformieren von Informationen aus XML-Dokumenten in entsprechende Zielformate zur Verfügung, wodurch sich XML sehr gut als Austauschformat zwischen Systemen eignet. Auf Grund dieser Eigenschaften erfährt XML derzeit eine rasante Verbreitung, so dass schon viele Daten im XML-Format vorliegen (vgl. IX 06/01).
Aus den genannten Eigenschaften lassen sich folgende Antworten auf die Motivationsfrage zum Einsatz von XML als Datenformat geben: Erstens können die speziellen Bedürfnisse verschiedener Nutzergruppen befriedigt werden, da verschiedenartige inhaltlichen Strukturen unterstützt werden. Zweitens ist die Möglichkeit der Weiterverarbeitung der Daten mit den genannten Werkzeugen durch das System, durch Dritte oder auch durch den Nutzer möglich und drittens können die Qualitäten von XML aus Austauschformat zum einbinden von Informationen aus heterogenen Datenquellen genutzt werden.
IV. Skalierbarkeit
Das anvisierte Einsatzgebiet der Benachrichtigungssysteme ist das Internet – also eine Umgebung, in der sowohl eine sehr große Anzahl von potentiellen Datenquellen als auch eine ebenso große Zahl potentieller Nutzer existiert. Um in einem solchen Umfeld ein performantes und leistungsfähiges Benachrichtigungssystem zu realisieren, ist eine hochgradige Skalierbarkeit unabdingbar.
Die technische Umsetzung dieser Anforderung ist die grundlegende Motivation für die Entwicklung von effizienten Verfahren zum Matching von Profil-Anfragen gegen XML- Dokumente: Denn es müssen alle eingehenden Dokumente mit den existierenden Profilen bezüglich der Übereinstimmung verglichen werden bei möglichst geringem Ressourcenaufwand. Ziel ist also die Gewährleistung der Funktionalität mit möglichst wenig Matches zwischen den Profilen und den Datenquellen – auf die Umsetzung dieser Anforderung konzentrieren sich die Ausführungen der nächsten Abschnitte.
B. Lösungsansätze: NiagaraCQ und XFilter
In diesem Abschnitt werden die Konzepte und Technologien beschrieben, die bei der Realisierung der beiden untersuchten Benachrichtigungssysteme verwendet werden. Die Ausführungen dienen als Grundlage zum Effizienzvergleich der Verfahren in Abschnitt C.
Beide Systeme sind im Zusammenhang größerer akademischer Forschungsprojekte entstanden. Da die Entwicklung der Systeme somit von den Zielsetzungen des jeweiligen Projekts determiniert wurde, soll ein kurzer Einblick in die Arbeitsfelder der Projekte und die Position der Systeme darin erfolgen.
I.1. Niagara Project / NiagaraCQ
NiagaraCQ wurde von Mitarbeitern des Niagara Project[1] entwickelt, in dem ein Net Data Management System – das Niagara Internet Query System – entstanden ist. Dieses System ermöglicht die Ausgabe von Auskünften über in XML-Dokumenten hinterlegten Informationen: Dabei stellt der Nutzer über eine GUI eine Anfrage in XML-QL (s.u.), welche die gewünschte XML-Substruktur und entsprechende Anfrageprädikate enthält. Als Datenquellen fungieren im Internet existente XML-Dokumente, deren URL und DTD dem System bekannt sind: in einer Anfrage kann die Datenquelle explizit angegeben werden oder das System referenziert alle ihm bekannten Datenquellen, deren DTD zu der Anfrage passt. Die Auskunft entspricht der in der XML-QL-Anfrage definierten Ausgabe. Die Bearbeitung einer Query wird mit Hilfe eines gewöhnlichen Query Prozessors – der Niagara Query Engine – vorgenommen (s. Abb. 1, vgl. Niagara).
Das Projekt besteht seit 1999 / 2000 und bietet auf seiner Website eine Implementierung als Public Domain Software an (vgl. Anhang 1).
NiagaraCQ stellt eine Erweiterung des Niagara Internet Query System dar (vgl. Anhang 1).
XFilter wurde im Rahmen des Broadcast Disks/DBIS – Projektes[2] entwickelt, welches sich mit Technologien zur Verbreitung von Informationen an viele Rezipienten beschäftigte. Dabei wurde unter anderem das DBIS Toolkit (Dissemination Based Information System Toolkit) entworfen – ein Framework für Informationsverteilungs-systeme, welches Aufgaben und Verantwortlichkeiten von folgenden Komponenten definiert: Erstens einer Data-Source-Library, in der die informationstragenden Datenquellen organisiert sind und in der eine eventuell nötige Formatwandlung erfolgt, zweitens von Information Brokern, welche die Datensourcen mit den Profilen über Keyword-Vergleiche matchen, und drittens eine Client Library, in der die Profile organisiert sind. Dabei sind die starken Ähnlichkeiten mit der oben vorgestellten allgemeinen Architektur eines Benachrichtigungssystems zu bemerken, wobei hier der Schwerpunkt auf der Informationsverteilung an die Profilinhaber und nicht auf einer eventbasierten Benachrichtigung liegt (vgl. DBIS-Toolkit).
Die Projektarbeit begann 1997 und scheint seit einiger Zeit eingestellt worden zu sein, wobei die Mitarbeiter in aufbauenden Projekte beschäftigt sind (vgl. Anhang 2).
XFilter ist eine Implementierung des DBIS-Toolkit (vgl. Anhang 2).
II. Architektur, Profildefinition, effektives Matching
Nach den einführenden Ausführungen werden nun die Realisierungen der beiden Systeme jeweils bezüglich der Architektur, der Profildefinition sowie der gewählten Ansätze zum effizienten Matching vorgestellt. Die Ausführungen beruhen auf den vorliegenden Systembeschreibungen[3] (vgl. NiagaraCQ und XFilter).
II.1. NiagaraCQ
Das NiagaraCQ ist die Erweiterung des Niagara Internet Query Systems um die Funktionalität eines Benachrichtigungssystems. Dazu wurde ein Verfahren zur Behandlung der Anfragen an das Niagara Internet Query System als Continuous Queries entwickelt, so dass ein Profilinhaber die gewünschten Auskünfte in einer automatisch aktualisierten Version erhalten kann. Dabei werden die existenten Mechanismen des Niagara Internet Query Systems zur Anfragebearbeitung und Datenquellenorganisation genutzt, so dass durch diese Erweiterung ein abgeschlossenes Benachrichtigungssystemen mit Invoker- und Observerfunktion sowie Filter- und Benachrichtigungskomponente entstanden ist (vgl. Anhang 1).
Die Architektur verdeutlicht das Erweiterungskonzept des Niagara Internet Query System durch NiagaraCQ: Die existenten Komponenten der Niagara Query Engine und der Niagara Search Engine (Abb. 1, rechts) werden zur Bearbeitung der Anfragen, bzw. zur Organisation der Datenquellen verwendet, während als neue Komponente der Continuous Query Processor (Abb. 1, links) das Modul zur Verwaltung von Continuous Queries darstellt (vgl. NiagaraCQ, Chap. 4). Wesentlich ist hierbei die Zusammenarbeit dieser Bausteine innerhalb des Systems.
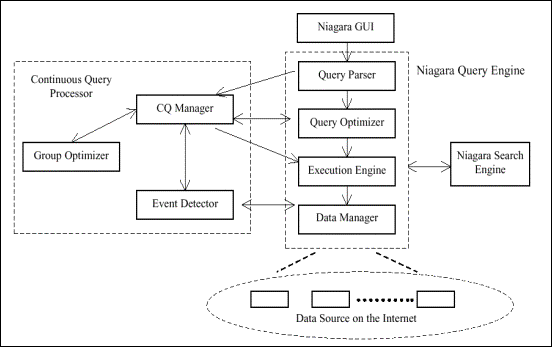
Abb. 1: Architektur NiagaraCQ
Dazu sollen kurz die Prozessabläufe zweier wesentlicher Systemfunktionalitäten besprochen werden: Erstens die Aufnahme eines neuen Profils (CQ) und zweitens die Schritte zur Ausführung einer CQ bis hin zur Benachrichtigung (vgl. Abb. 1).
Die Definition eines Profils geschieht über die Niagara GUI: dann erstellt der Query Parser (QP) den Query Plan[4] für die entstandene CQ und gibt die Informationen an den CQ Manager weiter (CQM). Dieser beauftragt den Event Detector (ED) mit der Überwachung der entsprechenden Events und gibt die CQ zur Verwaltung an den Group Optimizer weiter (GO, s. inkrementelle Gruppenoptimierung). Zur Ausführung einer CQ benachrichtigt entweder der Data Manager (DM) den ED bei der Änderungen einer Datenquelle für Change-Based CQs oder der ED befragt den DM über Änderungen in einem Zeitintervall für Timer-Based CQs. Der CQM beauftragt die Execution Engine (EE) mit der Ausführung der Query, wodurch die entsprechende Benachrichtigungsaktion getriggert wird (vgl. NiagaraCQ, Chap. 4).
|
Abb. 2: Definition einer CQ |
Abb. 3: Anfrage in XML-QL |


Die Definition einer CQ erfolgt mittels der Niagara Command Language, wobei folgende Eigenschaften erfasst werden: Der Name und die Benachrichtigungsaktion der CQ sowie Angaben über die Lebensdauer im System mit den Angaben START und EXPIRE sowie das Anführungsintervall über EVERY[5] (vgl. Abb. 2). Diese Deklarationen umfassen die eigentliche Anfrage, welche wie auch im Niagara Internet Query System in XML-QL formuliert wird (vgl. Niagara).
Als eine deklarative Anfragesprache erlaubt XML-QL Anfragen bezüglich (Sub-) Strukturen von XML-Dokumenten sowie Attributwerten und Dateninhalten von XML Elementen, wobei die Suchergebnisse sukzessiv als ein neues XML-Dokument ausgegeben werden können. Um komplexe Anfragen zu ermöglichen, können Vergleichsprädikate definiert sowie Join-Operationen über mehrere Datenquellen durchgeführt werden (vgl. XML-QL).
Das Beispiel in Abb. 3 zeigt die Syntax einer XML-QL Anfrage, welche die Stockquote der Intel Corporation (Kürzel INTC) aus einem lokalisiertem XML-Dokument ausliest (in „ .../quotes.xml“). Dabei wird in der Variable $g jene XML-Substruktur ab dem Element <Quotes> aus dem Dokument quotes.xml erfasst, in der das Element <Symbol> den Wert „INTC“ hat. Dieses XML-Konstrukt wird dann als Ergebnis der Anfrage ausgegeben (construct $g). Somit entspricht die Angabe des Wertes „INTC“ für das Element <Symbol> einem Selektionsprädikat: Mittels entsprechender Variablenkonstruktionen können dann Vergleichsprädikate, Joins über mehrere Datenquellen und entsprechende Ausgaben definiert werden, so dass komplexe Anfrageformulierungen mit dieser Anfragesprache möglich sind.
II.1.3. Ansatz zum effizienten Matching
Um ein, den Anforderungen des Einsatzgebietes entsprechend hohen Grad an Skalierbarkeit für die Bearbeitung der CQs durch NiagaraCQ zu gewährleisten, muss ein Verfahren zur Minimierung der für die Systemfunktionalität nötigen Matches zwischen Daten und Profilen zur Verfügung gestellt werden. Der hierfür gewählte Ansatz optimiert dazu die Organisation der Profile statt einer Modifikation der existenten Mechanismen zur Anfragefragebearbeitung, so dass die existenten Funktionalitäten direkt weitergenutzt werden können.
II.1.3.1.Die Hypothese
Die Optimierung von NiagaraCQ beruht der Hypothese, dass viele der eingehenden CQs eine gleichartige Struktur aufweisen. Dabei können gleichartige Anfragen in Gruppen zusammengefasst werden, so dass nur ein Match zur Überprüfung einer Gruppe gleichartiger Anfragen genügt. Somit soll zur Sicherstellung einer hochgradigen Skalierbarkeit eine effiziente Gruppierung gleichartiger Anfragen genügen, wie sie durch den Ansatz zur inkrementellen Gruppenoptimierung verwirklicht wird.
II.1.3.2. Ansatz zur inkrementellen Gruppenoptimierung
Grundlage der Gruppierung ist eine Definition der Gleichartigkeit von Anfragen, welche hier über die Gleichheit der „Expression Signatur“ vorgenommen wird. Abb. 4 zeigt die Expression Signature der Anfrage aus Abb. 3: Die Selektion der XML-Substruktur mit der Hierarchie „Quotes.Quote.Symbol“ aus dem Dokument quotes.xml über den Wert des Elements Symbol (hier „constant“). Die Expression Signature erfasst also die logische Struktur einer XML-QL Anfrage bezüglich der definierten XML-Substruktur und Prädikate: Ist diese Struktur bei zwei Anfragen gleich, so werden diese zu einer Gruppe zusammengefasst. Für eine solche Gruppe werden drei Dinge festgehalten: Die „Group Signature“, die „Group Constant Table“ und der „Group Plan“. Der inkrementelle Aspekt bezieht sich auf das Hinzufügen einer neuen CQ in das System: Nach der Erstellung des Query Plans der Anfrage durch den Query Parser wird dieser mit den existenten Group Plans abgeglichen: Existiert eine passende Gruppe, so wird die neue CQ zu dieser Gruppe hinzugefügt, sonst wird eine der Anfrage entsprechende neue Gruppe erzeugt.
|
Abb. 4: Expression Signature |
Abb. 5: Group Constant Table |
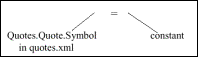

Da die Expression Signature aller Anfragen einer Gruppe gleich ist, entspricht die Group Signature der Expression Signature einer Anfrage aus der Gruppe: also ist die Expression Signature in Abb. 4 die Group Signature der Gruppe der Anfrage aus Abb. 3. Die Konstanten der einzelnen Anfragen einer Gruppe werden dabei in der Group Constant Table mit einem jeweiligen Destination Buffer[6] abgelegt. Abb. 5 zeigt einen Auszug aus der Gruppe der Anfrage aus Abb. 3: dabei wird z.B. für den Selektionswert „INTC“ die weiterverarbeitende Aktion i getriggert: Somit können die verschiedenen Queries in einer Gruppe unterschieden werden.
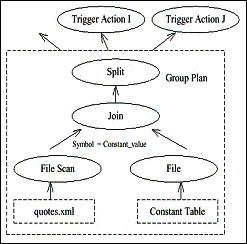
Durch die Dekomposition der Anfragen wird das zentrale Optimierungsziel dieses Ansatzes erreicht: denn für alle Anfragen innerhalb einer Gruppe muss bei Datenänderungs- oder Timer-Events nur ein einziger Match durchgeführt werden. Die Ausführung dieses Matches beschreibt der Group Plan (s. Abb. 6) : Zunächst wird einmalig die in der Group Expression definierte XML-Substruktur aus der Datenquelle als teures Matching herausgefiltert (File Scan Operator); das Ergebnis erhält alle Substrukturen aus der Quelle, die den Konstanten in der Group Constant Table entsprechen. Zur Weiterbearbeitung der einzelnen Anfragen werden für jede Konstante die im zugehörigen Destination Buffer hinterlegten Weiterverarbeitungs-schritte zugeordnet (Join Operator) und getriggert (Split Operator). Abb. 6 zeigt den Group Plan des bisherigen Beispiels: zunächst werden alle Substrukturen aus der Quelle quotes.xml gefiltert, die der Form Quotes.Quote.Symbol entsprechen. Dann werden die weiterführenden Verarbeitungsschritte gemäß der Destination Buffer für die einzelnen Konstanten ausgelöst – für „INTC“ also „Dest_i“ (s. Abb. 5).
|
Abb. 6: Group Plan |
Abbildung 7: Group Plan nach Query Split |
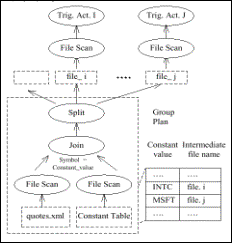
Die Effizienz dieses Gruppierungskonzepts wird durch den sogenannten „Query Split“ gesteigert: Hierbei werden komplexe CQs aufgespalten und die daraus entstehenden Teilanfragen jeweils einer Gruppe zugeordnet. Nehmen wir als weiterführendes Beispiel eine komplexere Anfrage: Es sollen die Adressen aller Unternehmen aus dem Dokument companies.xml ausgeben werden, deren Stockquote in quotes.xml niedriger als 5 $ liegt . Zur Bearbeitung dieser Anfrage muss eine Selektion über die Daten aus quotes.xml laufen und es muss ein Join mit den Unternehmensdaten aus companies.xml durchgeführt werden.
Dazu wird die Anfrage in zwei Teilanfragen zerlegt, die jeweils einer eigenen Gruppe angehören[7]. Um das Ergebnis der Teilanfragen wieder zusammenzusetzen, wird das Ergebnis der ersten Abfrage in einem „Intermediate File“[8] zwischengespeichert: Der Split-Operator der ersten Teilanfrage – im Beispiel die Selektion aus quotes.xml – triggert die Ausführung der Gruppe der zweiten Teilanfrage, wobei der Intermediate File dann als Datenquelle fungiert. Somit können mit Hilfe weniger Gruppen auch komplexe Anfragen behandelt und die Performance des Systems gesichert werden, da die alle Gruppen nur einen relativ simplen Group Plan bearbeiten müssen.
Um die Anzahl der nötigen Matches zu minimieren, werden weitere Techniken eingesetzt: Erwähnenswert ist zum einen das Caching, wobei die Ergebnisse durchgeführter Matches gespeichert und wiederverwendet werden können, und zum anderen der Einsatz von Delta Files, in denen Änderungen der Datenquellen geloggt werden (so muss für Timer Based CQs kein erneuter Match durchgeführt werden).
II.2. XFilter
Als Implementierung des DBIS Toolkit (s.o.) erweitert XFilter die Vorgaben des Frameworks um die Funktionalität eines Benachrichtigungssystems: auch hier können Profile definiert werden, um individuell relevante Informationen aus eingehenden Informationen zu filtern. Diese Zielsetzung wird als selektive Informationsverteilung bezeichnet: es sollen Dokumente mit neuen Informationen an die Profilinhaber verteilt werden und nicht wie bei NiagaraCQ Auskünfte aus existierenden Dokumenten erzeugt werden (vgl. XFilter, Chap. 1). Der Fokus liegt auf dem Filterprozess eingehender Dokumente gegen die Profile; das System soll dabei als Komponente zur Einbindung in andere Informationssysteme dienen (vgl. XFilter, Chap. 2).
II.2.1. Architektur
Die Architektur von XFilter zeigt vier wesentliche Komponenten auf: zunächst die Parser für die Inputs (den XML Parser für eingehende Dokumente und den XPath Parser für die Profile), dann die Filter Engine zum Marching der Inputs und das Data Dissemination Modul, welches die Dokumente in geeigneter Weise an die Nutzer weiterleitet (vgl. Abb. 8). Bis auf die Invokerfunktionalität entspricht dieser Aufbau der allgemeinen Architektur eines Benachrichtigungssystems (vgl. Abschnitt A.I).
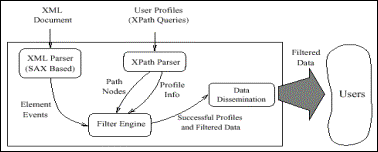
Abbildung 8: Architektur XFilter
Die beiden wesentlichen Prozesse werden hier nur kurz angesprochen, da eine ausführlichere Erläuterung im Zusammenhang der Filter Engine erfolgen wird: Eine neue Query wird vom XPath Parser ausgewertet und als Continuous Query gespeichert. Das Feuern einer CQ wird durch den Eingang eines neuen Dokuments ausgelöst: Die vom XML Parser detektierten Events lösen die Ausführung der Filter Engine aus. Bei einer Übereinstimmung mit einem Profil wird das Dokument an den entsprechenden Nutzer weitergeleitet.
Die Definition einer Anfrage erfolgt in XPath, einer Adressierungssprache für XML.
In XPath können Expressions als globale oder relative Pfaddefinitionen formuliert werden, mittels derer der Baum eines XML-Dokuments traversiert werden kann. Die Auswertung ergibt entweder eine XML-Substruktur oder den Wert bzw. Inhalt eines Elements. Die Bestandteile einer XPath Expression werden als Location Step bezeichnet: Zu jedem Location Step können Filterprädikate definiert und es können primitive Funktionen auf XPath Expressions aufgerufen werden (vgl. XPath). Beispiele für XPath Expressions werden bei der Erläuterung der Filter Engine behandelt (s.u.).
Der Einsatz von XPath in XFilter dient der Auswertung der Anfragen: Enthält ein Dokument die in der Anfrage definierte Pfadstruktur, so wird das Dokument an den Nutzer weitergeleitet.
II.2.3. Ansatz zum effizienten Matching
Die Optimierung des Matching von eingehenden Dokumenten und den Profilen wird in XFilter durch einen Filtermechanismus in der Filter Engine vorgenommen. Die Funktionsweise der Filter Engine sowie weiterführende Filteralgorithmen werden im Folgenden erläutert.
II.2.3.1.Filter Engine
Die Funktionsweise der Filter Engine wird chronologisch am Prozessablauf der Aufnahme einer neuen Anfrage und den Abläufen des Matchings eines neuen Dokuments gegen existierende Anfragen beschrieben.
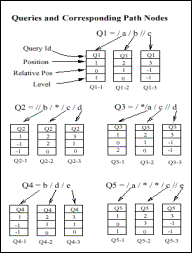
Zunächst wird die XPath Expression einer neuen Anfrage durch den XPath Parser in eine Final State Mashine (FSM) zerlegt: Die FSM wird später beim Matchen durchlaufen. Jeder Location Step der XPath Expression entspricht dabei einem State der FSM; ein solcher State wird als „Path Node“ (PN) bezeichnet. Abb. 9 zeigt diese Zerlegung von mehreren XPath Expressions: Die Beispiele in den Ausführungen beziehen sich dabei auf die Query Q1=/a/b//c . Diese wird in drei PNs zerlegt, da sie drei Location Steps aufweist: Jeder PN enthält folgende Werte: eine „Query ID“ (Q1), mit der die Zugehörigkeit zu einer Query festgehalten wird, die „Position“ ist die Statenummer innerhalb der FSM (hier: 1 für den ersten Location Step a). Die „Relative Position“ beschreibt die XML-Hierarchiestufe eines PNs relativ zu den anderen PNs einer Query: dieser Wert ist –1 für Location Steps mit Descendant Operator (hier: Q1-3), 0 für den ersten Location Step und mit 1 addiert für jeden weiteren. Der letzte Wert „Level“ erfasst die Hierarchiestufe zur Existenzprüfung des PNs im XML-Dokument, dessen Wert vom Zustand der Query abhängig ist. Neben diesen Werten enthält jeder PN ein NextPathNodeSet[9] mit Pointern auf die nachfolgenden PNs (Q1-1 zeigt auf Q1-2).
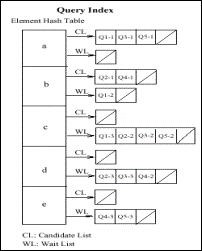
Alle Anfragen werden im „Query Index“ verwaltet: Dies ist eine Hashtable, in der die PNs ihrem entsprechenden XML Elementnamen zugeordnet sind. Dabei gibt es zwei Arten von Listen, in denen die einem Elementnamen zugehörigen PNs hinterlegt sind: „Candidate-Listen“ (CL) und „Wait-Listen“ (WL). Dabei steht für jede Query derjenige PN in der Candidate-Liste, der den Initialzustand der FSM der Query repräsentiert, während alle folgenden State-PNs in der Wait-Liste stehen. Q1-1 steht also in der Candidate-Liste für a, Q1.2 in der Wait-Liste für b, etc (vgl. Abb.9).
|
Abb. 9: XFilter Path Nodes |
Abb. 10: XFilter Query Index |
Wenn nun ein neues Dokument in das System eintritt, so durchläuft es zunächst den XML Parser, der drei Arten von Events im Dokument detektiert: Start Elemente, End Elemente und Element Characters (die eigentlichen Daten in einem XML Element). Für jeden diese Events steht jeweils an Handler zur Verfügung.
Wird der Start Element Handler aktiviert, so überprüft er im Query-Index alle PNs aus der Candidate-Liste des jeweiligen Elementnamens: Dabei werden der Levelwert und weitere Unteranfragen aus Filterdefinitionen überprüft. Alle Queries, deren Initialzustands-PN diese Überprüfung bestehen, werden in den nächsten Zustand der FSM transiert: Das heißt, dass der Initialzustands-PN aus seiner Candidate-Liste gelöscht und der folgende PN in die Candidate-Liste seines Elementnamens verschoben wird. Im Beispiel würde also Q1-1 aus der Candidate-Liste von ‚a’ entfernt und Q1-2 aus der Wait-Liste in die Candidate-Liste von ‚b’ verschoben. Dabei werden die Werte für die Relative Position und das Level angepasst, um die Filterfunktionalität aufrecht zu erhalten.
Bei Aktivierung des End Element Handler wird jener Zustand der FSM wiederhergestellt, bevor der korrespondierende Start Handler aktiviert wurde: Dies ist für den Fall, dass die FSM einer Query auf Grund von zutreffenden Restriktionen im Filter- oder Levelcheck (s.o.) nicht in den nächsten State transiert wurde. Dabei wird der entsprechende PN aus seiner Candidate-Liste in die Wait-Liste verschoben.
Die Auswirkungen des Element Characters Handler sind identisch mit denen des Start Element Handler: auch er transiert die passenden Queries in den nächsten State ihrer jeweiligen FSM. Dabei überprüft er nicht strukturelle Filterdefinitionen des Location Steps einer XPath Expression, sondern mögliche Restriktionen bezüglich des Dateninhaltes eines Location Steps.
Dieser Prozess wird solange wiederholt, bis die FSM einer Query ihren Final State erreicht hat (wenn der letzte PN der Query die Überprüfung besteht): Dann wird das Dokument als der Anfrage entsprechend eingeordnet (da die Pfadstruktur der XPath Expression im Dokument enthalten ist, s.o.) und über das Data Dissemination Modul an den Profilinhaber weitergeleitet.
II.2.3.2. Erweiterte Filteralgorithmen
Der beschriebene Filterprozess in der Filter Engine wird als „Basic Filtering Algorithm“ bezeichnet: Aufbauend werden zwei erweiterte algorithmische Verfahren vorgestellt, welche die Performance des Basic Algorithm verbessern.
Zunächst das List Balancing: Hierbei werden die Candidate-Listen innerhalb des Query-Index ausbalanciert. Dazu wird als Initialzustands-PN nicht wie beim Basic Algorithm der erste PN der Query genommen, sondern derjenige PN, dessen Candidate-Liste im Query-Index am kürzesten ist. Dieser PN, als „Pivot Node“ bezeichnet, wird dann als Präfix vor die eigentlichen States der FSM gesetzt. Somit muss ein Event Handler weniger potentielle PNs in der Candidate-Liste untersuchen, was in den Performancetests deutliche Vorteile hervorbringt (vgl. XFilter, Chap. 6).
Das zweite Verfahren wird als Prefiltering bezeichnet: Dabei werden vor der Ausführung der Filter Engine alle Queries aus dem Query-Index entfernt, die nicht alle Elemente des eingehenden Dokuments aufweisen. Die Vorfilterung wird mittels einer „Occurrence Table“ vorgenommen, in der das Vorkommen der Elemente des Dokuments mit den Location Steps der XPath Expressions der existenten Queries verglichen wird. Auch dieser Ansatz bringt Performancegewinne – vor allem dann, wenn er mit dem List Balance Algorithmus kombiniert wird (vgl. XFilter, Chap. 6).
C. Vergleich der Lösungsansätze
Nach den Beschreibungen der beiden Benachrichtigungssysteme werden nun deren Verfahren zum Matching strukturierter Anfragen gegen XML-Dokumente verglichen. Der Vergleich wird durch eine Betrachtung der wesentlichen Unterschiede der beiden Systeme vorgenommen, so dass eine umfassende Aussage über die Effizienz der Verfahren getroffen werden kann.
Für die Betrachtung der Unterschiede ergeben sich auf Grund der Systemstrukturen drei Aspekte: zunächst soll ein Vergleich der Ausdrucksfähigkeit der beiden unterschiedlichen Profildefinitionssprachen und deren Einsatz im jeweiligen System die Qualität möglicher Anfragen an die Systeme gegenüberstellen, welche sich in Zusammenhang mit den funktionalen Intentionen der Systeme stellen lassen. Der zweite Aspekt vergleicht den Grad und die Qualität der erreichten Skalierbarkeit der Systeme: Also die eigentliche Matching-Effizienz der Verfahren. Als dritter Aspekt drängt sich auf Grund der sehr unterschiedlichen Herangehensweisen eine genauere Betrachtung der gewählten Ansätze zum effizienten Matching auf: Dabei soll auf der Grundlage der allgemeinen Architektur von Benachrichtigungssystemen die jeweiligen Ansatzpunkte für die Optimierung bestimmt und deren Unterschiede herausgearbeitet werden.
I. Ausdrucksfähigkeit der Profildefinitionssprachen
Die Unterschiede in der Ausdrucksfähigkeit der verwandten Profildefinitionssprachen resultiert aus deren unterschiedlichen funktionalen Konzeptionen: XML-QL soll als eine deklarative Anfragesprache für XML-Dokumente eine ähnliche Funktionalität erfüllen wie SQL im Bereich der relationalen Datenverarbeitung (vgl. XML-QL), während XPath als Adressierungssprache für XML-Dokumente entwickelt worden ist, welche vor allem von anderen Verarbeitungswerkzeugen wie XSL oder XPointer verwenden werden soll (vgl. XPath).
Um die Unterschiede in der Qualität möglicher Anfragen an die Systeme herauszustellen, wird im Folgenden nach dem Vergleich der Ausdrucksfähigkeit der Sprachen deren Einsatz im jeweiligen System betrachtet, woraus sich dann unterschiedliche Schwerpunktsetzungen in der funktionalen Intention der Systeme ableiten lassen.
Die Unterschiede in der Ausdrucksfähigkeit der Sprachen können an Hand von folgenden drei Kriterien gezeigt werden: Erstens an Hand der Selektionsqualität bezüglich der Art der Informationsselektion, zweitens die Definitionsmöglichkeit von Informationsquellen und drittens die unterstützte Informationsaufarbeitung durch die Art der Ergebniskonstruktion.
Die Selektionsqualität von XML-QL lässt dich wie folgt beschreiben: Eine Anfrage extrahiert aus einer XML-Datenquelle mit bekannter Struktur jene Informationen, die den definierten Selektionsprädikaten genügen. Es können also gewünschte Informationen aus einem Informationsangebot herausgesucht werden, wie zum Beispiel die Stockquote einer bestimmten Organisation in der Abfrage aus Abb. 3 (s.o.). Somit lässt sich der funktionale Charakter der Selektionsqualität vornehmlich als Wertselektion im Sinne einer Informationsgewinnung beschreiben, in der die Strukturselektion der Anfrage lediglich als Teil der Prädikatformulierung fungiert. Im Unterschied dazu erlaubt eine in XPath formulierte Anfrage die Adressierung von XML-Strukturen in einem unbekannten XML-Dokument, so dass Informationen über den Inhalt eines neuen Dokuments gewonnen werden können. Erweitert werden diese Funktionalitäten durch mögliche Definitionen von Filtern und elementaren Funktionen für bestimmte XML-Substrukturen, wodurch eine höhere Aussagequalität über den Inhalt eines unbekannten Dokuments erreicht wird. So gibt zum Beispiel die Path Expression P = sum(//product [price > 100])die Summe aller XML-Subtrees des befragten Dokuments, die das XML-Element product enthalten und dessen Attribut price größer als 100 Geldeinheiten ist[10]. Die Charakteristik von XPath im Gegensatz zu XML-QL lässt also sich als reine Strukturselektion begreifen.
Die Definitionsmöglichkeit von Informationsquellen zeigt einen sehr wesentlichen Unterschied der beiden Sprachen auf: Während bei XML-QL die explizite Angabe der Datenquelle in der Anfrage gefordert wird (vgl. XML-QL), kann eine XPath Expression nur von außen, also applikationstechnisch an ein Dokument heran-getragen werden (vgl. XPath). XML-QL arbeitet also mit bekannten Datenquellen[11], während XPath an unbekannte XML-Dokumente herangetragen wird.
Ähnlich ist der Unterschied bezüglich des Kriteriums zur Unterstützung der Ergebnis-konstruktion: XML-QL erlaubt die explizite Definition der Ausgabe eines Anfrage-ergebnisses als Teil der Anfrageformulierung über die „construct“-Angabe (vgl. Abb.3). XPath gibt im Falle der positiven Evaluation eines XML-Dokuments den entsprechenden XML-Subtree des Dokuments zurück – falls die Path Expressions nicht im Dokument enthalten ist, wird FALSE zurückgegeben (vgl. XPath). Also ermöglicht XML-QL dem Nutzer eine selbstdefinierte Aufbereitung der Ergebnisse, während XPath nach der Prüfung einen Wert für eine mögliche Weiterverarbeitung der Informationen liefert.
Auf Grund dieser Unterschiede lässt sich folgende Aussage über die funktionalen Konzeptionen der Sprachen im Hinblick auf das hier untersuchte Einsatzgebiet machen: Während XML-QL zur aufarbeitenden Informationsgewinnung aus bekannten Datenquellen dient, ist mit Hilfe von XPath eine inhaltliche Evaluation eines unbekannten Dokuments möglich.
Diese Aussage wird bei der Betrachtung des Einsatzes der Sprachen in den Systemen gefestigt. Dabei unterstützt NiagaraCQ, bzw. das erweiterte Niagara Internet Query System alle Funktionalitäten von XML-QL: Über eine GUI wird eine wertselektierende Anfrage an die dem System bekannten Datenquellen gestellt sowie die Ergebnisaussage definiert[12]. Somit stellt das System an eine Anwendung innerhalb des von XML-QL intendierten Einsatzgebiets dar: ein Auskunftssystem für Informationen aus im Internet existenten XML-Dokumenten (vgl. Niagara). XFilter nutzt XPath zur sequentiellen Evaluierung von eingehenden Dokumenten bezüglich der in den Profilen definierten Interessensgebieten der Nutzer, wobei die struktur-selektierende Funktionalität sowie die implizite Ergebnisrückgabe als Basis des Filtermechanismus dienen. Somit gilt auch für XFilter, dass die inhaltsevaluierende Qualität von XPath Expressions als Profildefinition die Anforderungen aus der funktionalen Intention von XFilter als Dokument-Filter-System abdeckt (vgl. XFilter).
Aus dem Vergleich wird deutlich, dass XML-QL zwar komplexere und informations-trächtigere Anfragen erlaubt als XPath, aber die Fähigkeiten der gewählten Anfragesprache jeweils den Anforderungen bezüglich der funktionalen Intentionen der Systeme in ausreichender Weise genügen[13].
II. Skalierbarkeit
Dieser Aspekt befasst sich mit der eigentlichen Effizienz, die durch die Systeme zum Matching von unstrukturierten Anfragen gegen XML-Dokumente erreicht wird. Dabei soll sowohl der quantitative als auch der qualitative Aspekt der Verfahrenseffizienz Berücksichtigung finden.
Beide Systeme zeigen in den quantitativen Tests der jeweiligen Autoren durchaus annehmbare Ergebnisse – die Verarbeitung mehrerer 10.000 Anfragen im Sekundenbereich (vgl. Testergebnisse jeweils in NiagaraCQ / XFilter). Allerdings sind diese Zahlen nicht für einen aussagekräftigen Vergleich geeignet, da sie unter ungleichen Voraussetzungen und von den Entwicklern der Systeme selber durchgeführt wurden.
Interessanter ist allerdings ein qualitativer Vergleich bezüglich der Skalierbarkeit in unterschiedlichen Anfrageumgebungen bezogen auf den Homogenitätsgrad der vorliegenden Anfragen. Die Anfragenhomogenität soll dabei wie folgt verstanden werden: gleich seien Anfragen, die genau gleich sind, gleichartig seien Anfragen, deren Expression Signature gleich ist (siehe dazu Abschnitt B, II.1.3.2), und ungleich seien Anfragen, die gänzlich verschieden sind.
Das Verhalten von NiagaraCQ unter diesem Betrachtungshintergrund ist relativ einfach zu analysieren: Die Effizienzoptimierung beruht auf der inkrementellen Gruppenoptimierung. Diese beruht auf der hypothetischen Annahme, dass viele Anfragen die gleiche Struktur aufweisen und somit eine hohe Skalierbarkeit durch eine entsprechende Gruppierung gesichert werden kann. Je mehr Profile allerdings eine unterschiedliche Expression Signature aufweisen, desto mehr Gruppen müssen gebildet werden: Also ist die erreichte Skalierbarkeit je größer, desto homogener die Anfragehomogenität bezüglich der Gleichartigkeit von Anfragen ist.
Der Ansatz von XFilter zeigt ein anderes Verhalten: Die Queries werden bezüglich der Elementnamen im Query Index gehalten und die Traversion der FSM einer Anfrage ist unabhängig von den anderen Anfragen im System (vgl. Abschnitt B, II.2.3.1); Somit ist der Filtermechanismus unabhängig von der Gleichartigkeit von Anfragen. Allerdings besteht eine andersartige Abhängigkeit: Alle Anfragen mit dem gleichen Initialzustands-PN im Query Index müssen vom Event Handler als potentielle Kandidaten geprüft werden. Damit ist die Skalierbarkeit umso größer, je heterogener die Anfragehomogenität bezüglich der Gleichheit von Anfragen ist[14].
Dieser Vergleich zeigt zunächst, dass die Skalierbarkeit der Systeme in gegen-sätzlicher Weise von der Anfragenhomogenität abhängig ist. Leider fehlen jedoch empirische Daten über die Anfragenhomogenität, um hier weiterführende Aussagen vornehmen zu können. Allerdings ist hier die unterschiedliche Art der Homogenität entscheidet, von der die Skalierbarkeit der Systeme abhängt: denn NiagaraCQ ist von der Gleichartigkeit abhängig, während XFilter von der Gleichheit abhängig ist. Dabei stellt generell die Menge der gleichen Anfragen im Allgemeinen eine sehr kleine Menge der gleichartigen Anfragen dar[15], so dass die Abhängigkeit der Skalier-barkeit von der Gleichartigkeit der Anfragenhomogenität von NiagaraCQ[16] einen sehr viel stärkeren Einfluss auf die tatsächlich zugesicherte Skalierbarkeit hat als die Abhängigkeit der Skalierbarkeit von XFilter bezüglich der Gleichheit von Anfragen.
III. Ansätze zum effizienten Matching
Nach der differenzierten Betrachtung der Qualität möglicher Anfragen und des erreichten Skalierbarkeitsgrades verbleiben als letzter Vergleichsaspekt der Systeme die sehr unterschiedlichen Ansätze zum effizienten Matching. Um diese Unterschiede herauszuarbeiten, sollen die Systeme bezüglich allgemeiner Prozessabläufe in einem Benachrichtigungssystem gegenübergestellt und so die jeweiligen Ansatzpunkte für die Optimierung des Matching bestimmt und verglichen werden.
Zunächst müssen hierzu die allgemeinen Prozessabläufe eines Benachrichtigungs-system klassifiziert werden, wozu die Aufgabenverteilung der Komponenten in der oben erläuterten allgemeinen Architektur von Benachrichtigungssystemen heran-gezogen wird (s. Abschnitt A.I). Dabei hat zunächst der Invoker die Aufgabe, die Informationsquellen des Systems (Object Repository) zu verwalten. Der Observer überwacht die Änderungen in den Datenquellen und stellt diese als Eventmeldungen der Filterkomponente für den Matchingprozess zur Verfügung. Die Filterkomponente ist unter dem hier gewählten Betrachtungsaspekt das Kernstück des Systems: Hier wird das Matching der eingehenden Events mit den existenten Profilen aus dem Profile Repository durchgeführt. Die ermittelten Informationen werden durch die Benachrichtigungskomponente dann an die Profilinhaber in geeigneter Form weitergeleitet (vgl. Hinze S. 5 ff).
NiagaraCQ, bzw. das erweitere Niagara Internet Query System weist diesbezüglich folgende Prozessstrukturen auf: Die Funktionalität des Invokers übernimmt die Niagara Search Engine, der Event Detector dient als Observer während die Execution Engine die Filter- und die Benachrichtigungsfunktionalität erfüllt (vgl. Abb. 1). Der Optimierungsansatz über die inkrementelle Gruppenoptimierung ist als Optimierung des Profile Repositories zu verstehen, da hier die Profile der Systemfunktionalität angepasst werden, bevor sie in der Filterkomponente mit den eingehenden Events gemacht werden. Durch diesen vorgezogenen Verarbeitungs-schritt sind im eigentlichen Filterprozess weniger Matches durchzuführen, wodurch die Effizienz dieses Prozesses gesteigert wird. Dieser Ansatz beruht also in einer Aufteilung der Aufgaben der Filterkomponente in die vorgelagerte Optimierung der Profile und den eigentlichen Matching-Prozess.
Die Prozessverteilung an die Komponenten des XFilter-Systems ist wie folgt zu beschreiben: Der XML-Parser detektiert die Events eingehender Dokumente und stellt somit den Observer dar. Die Filterkomponente umfasst den Query Index und die Eventhandler des Filtermechanismus in der Filter Engine, während das Data Dissemination Modul die Benachrichtigungskomponente darstellt: Hier fehlt allerdings – zumindest in der vorliegenden Systembeschreibung – eine Komponente für die Invokerfunktionalität (vgl. Abb. 8). Der Optimierungsansatz liegt hier im oben beschriebenen Filtermechanismus, in dem alle Profile gleichzeitig gegen die eingehenden Events gemacht werden. Dabei wird dieser Prozess nicht aufgeteilt, sondern über ein algorithmisches Verfahren in seiner Leistungsfähigkeit optimiert.
Aus diesem Vergleich ergeben sich zwei Erkenntnisse: Erstens stellt NiagaraCQ bezüglich der unterstützten Prozesse ein abgeschlossenes Benachrichtigungssystem dar, während XFilter ein XML-Dokumenten-Filter-System als Komponente zur Einbindung in größere Informationssysteme darstellt. Als zweite Erkenntnis ist ein wesentlicher Unterschied in der Konzeption der gewählten Ansätze zum effizienten Matching festzuhalten: NiagaraCQ optimiert das Nadelöhr der Filterkomponente durch Aufgabenverteilung an verschiedene Komponenten, während XFilter einen algorithmischen Ansatz für den Filterprozess bietet.
Der Vergleich der Verfahren zum Matching von strukturierten Anfragen gegen XML-Dokumente von NiagaraCQ und XFilter hat folgende Ergebnisse erbracht:
Beide Systeme realisieren XML-basierte Benachrichtigungssysteme und haben zur Sicherstellung eines gewissen Grades an Skalierbarkeit Optimierungsverfahren für das Matching von Profilen gegen Änderung in den Datenquellen entwickelt: Allerdings bestehen wesentliche Unterschiede in den funktionalen Zielsetzungen und den jeweiligen Matching-Verfahren.
Der erste wesentliche Unterschied ergibt sich aus der Betrachtung der Qualität möglicher Anfragen in Zusammenhang mit den funktionalen Intentionen der Systeme: NiagaraCQ stellt unter Verwendung von XML-QL als vornehmlich wertselektierender Anfragesprache die Funktionalität eines Auskunftssystems dar, während XFilter die Fähigkeiten von XPath bezüglich der strukturselektierenden Evaluation von XML-Dokumenten zur Realisierung eines Dokumenten-Filter-Systems nutzt. Hierbei ist also Folgendes festzuhalten: Erstens stellen die Systeme unterschiedliche Arten von Benachrichtigungssystemen dar und zweitens, dass die funktionalen Konzeptionen der Profildefinitionssprachen mit den funktionalen Intentionen des jeweiligen Systems übereinstimmen, wobei die Ausdrucksfähigkeit der verwendeten Sprache den qualitativen Anforderungen für die jeweilige Systemfunktionalität genügen.
Den zweiten wesentlichen Unterschied der Systeme stellt die Qualität des erreichten Skalierbarkeitsgrades dar: Wie die Untersuchung des Verhaltens der Systeme unter dem Aspekt des Homogenitätsgrades der gestellten Anfragen herausstellt, sind beide Verfahren von der Anfragenhomogenität abhängig. Allerdings ist die Skalierbarkeit des Ansatzes der inkrementellen Gruppenoptimierung von NiagaraCQ bezüglich der Gleichartigkeit von Anfragen abhängig, während die Abhängigkeit der Skalierbarkeit des XFilter-Filtermechanismus lediglich von der Gleichheit der Anfragen bestimmt wird – und das auch nur beim Basic Filter Algorithmus: Damit ist der Effizienzgewinn des Ansatzes von NiagaraCQ in sehr viel höherem Maße von der Umgebungs-situation abhängig ist als derjenige von XFilter. Dies ist ein wesentlicher Qualitätsunterschied der Verfahren, da der zugesicherte Grad an Skalierbarkeit bei XFilter somit stabiler ist als der von NiagaraCQ.
Dieser qualitative Unterschied der Verfahren wird verdeutlich durch die Erkenntnisse aus dem Vergleich der gewählten Ansatzpunkte zur Optimierung der Verfahren: In beiden Systemen wird zwar die Funktionalität der Filterkomponente optimiert – allerdings beruht der Ansatz von NiagaraCQ auf einer Aufgabendelegation durch die vorgelegten Verarbeitungsschritte der Gruppenoptimierung ohne eine Optimierung des eigentlichen Filterprozesses, wogegen der Ansatz von XFilter genau diesen mit dem Filtermechanismus optimiert. Dies bedingt die stärkere Abhängigkeit des Ansatzes von NiagaraCQ von der Anfragenhomogenität, da der Filterprozess weiterhin über einen gewöhnlichen Query Prozessor läuft, während die Filter Engine von XFilter einen für das Einsatzgebiet optimierten Query Prozessor darstellt.
Als abschließende Bewertung lässt sich folgende Aussage zusammenfassen:
NiagaraCQ stellt ein abgeschlossenes, XML-basiertes Auskunftssystem mit der Möglichkeit zur Formulierung komplexerer Anfragen dar, welches allerdings seine Performance und Skalierbarkeit nur durch das ausgefeilte Zusammenspiel von Technologien darstellt, wogegen XFilter ein XML-Dokumenten-Filter-System als Komponente zur Einbindung in ein größeres Informationssystem realisiert, welches zwar durch einen algorithmischen Filtermechanismus einen höheren Grad an Skalierbarkeit zusichert, aber nur weniger aussagekräftige Anfragen zulässt.
|
DBIS-Toolkit |
|
|
|
Altinel, M.; Aksoy, D.; Baby, T., u.a:
DBIS-Toolkit: Adaptable Middleware unter:
http://www.cs.berkeley.edu/~franklin/Papers/DBISsigmod99.html |
|
Hinze |
|
|
|
Hinze, A.; Faensen, D.: A Unified Model of
Internet Scale Alerting Services. Freie Universität Berlin,1999. unter:
http://www.inf.fu-berlin.de/~hinze/projects/publications/icsc99 |
|
IX 06/01 |
|
|
|
Behme,
H.; Ziegler, C.; Klever, u.a: XML überall. XML, XML-Server, XML-Programmierung,
Microsofts XML-Strategie. IX 06/2001, S. 52 – 80. |
|
Mobile Delivery |
|
|
|
Ozen, B.; Kilic, O.; Altinel, M.; u.a.:
Highly Personalized Information Delivery to Mobile Clients. Turkey / USA, 2001. unter:
http://www.erdc.metu.edu.tr/papers/cqmc_longVersion.pdf |
|
Niagara |
|
|
|
Naughton, J.; Chen, J.; Kang, J., u.a.: The
Niagara Internet Query System. University of Wisconsin-Madison, 2000. unter:
http://www.cs.wisc.edu/~jai/papers |
|
NiagaraCQ |
|
|
|
Chen, J.; DeWitt, D.J.; Tian, F.; Wang, Y.: NiagaraCQ: A Scalable Continuous Query
System for Internet Databases. SIGMOD Conference, 2000. |
|
O’Neil |
|
|
|
O’Neil, P.; O’Neil, E.: Databases. Principles, Programming, and Performance. 2. Aufl.. San Diego,
Morgan Kaufmann Publishers 2001. |
|
XFilter |
|
|
|
Altinel, M.; Franklin, M.J. : Efficient
Filtering of XML Documents for Selective Dissemination of Information. VLDB,
2000. |
|
XML |
|
|
|
DuCharme, B.: XML: The Annotated
Specification. Prentice
Hall, 1999. (weitere
Informationen unter: http://www.w3c.org/XML/ ) |
|
XML-QL |
|
|
|
Deutsch, A.; Ferandez, M.; Florescu, D.;
u.a.: A Query Language for XML. 1998 unter: http://www.w3.org/TR/NOTE-xml-ql |
|
XPath |
|
|
|
Clark, J.; DeRose, S.: XML Path Language
(XPath). W3C Recommendation, 1999. unter:
http://www.w3.org/TR/xpath |
1
Mailkorrespondenz
NiagaraCQ:
·
Meine Anfrage, 07.06.2001:
Hello,
my name is Michael Stollberg, a student of Computer
Science at the Freie Universität Berlin, Germany. I'm doing a studies work on
comparison of systems that are matching continuous query profiles with XML
documents - and one of these systems is your NiagaraCQ. Therefore I would like
to address you with some questions on your NiagaraCQ system: I would be
glad if you my give me some answers so I can understand the system in a
better way.
Well, here are my questions then:
1) Am I right to say that NiagaraCQ is the
attempt to extend the Niagara Internet Query System by an notification system
based on the concept of continuous queries?
2) As far as I understood your paper, NiagaraCQ is
based on the hypothesis that many continuous queries added to the system will
be equal (= have the same expression signature). Do you have any kind of
empirical proof for this hypothesis? And what will happen to the system if
there will only be heterogeneous continuous queries?
3) This question is the most important one to me
because it concerns the comprehendence of the incremental group optimization
approach, especially the query split:
As far as I got is: if there is a complex query it can
be split into easier parts. These parts my belong to different existing groups
in the system. The parts of the query will be executed and the result of the
first part will be stored in an intermediate file which will act as the data
source for the second part and so on.
Now the question: How does the system know which query
parts belong to which profile? Or may this belonging be handled by the stored
constants in the different constant tables of the query parts?
If this is done by the constants: Who or what decides
in which way a new continuous query is split? Is this done by the Group
Optimizer - this must be a very complex algorithm, mustn't it?
4) Last but not least: Is there any
implementation of NiagaraCQ? I have seen and used the software of the Niagara
Internet Query System - do you have anything like this for NiagaraCQ, too?
I would like to thank you very much if you read this
mail up to this point and I would be really glad to receive any answer to these
questions - I hope you do not feel like been attacked by questions like 1) and
2) :))
Thanks for your time and greetings from
Berlin MICHAEL STOLLBERG
·
Antwort, 08.06.2001 (nur Antworten):
zu 1)
You can think in that way. We view NiagaraCQ is a part of the whole
Niagara Internet Query (common query and continuous query) system.
zu 2)
One example is the forms on web sites (book sellers, stock sites, etc.)
that allow users to put different constant values to query. If all queries are
totally different, grouping is
definitely not helpful.
zu 3)
After each query is split, the upper level queries will have a scan
operator taking the correct intermediate file name as input. Thus query will be
triggered for execution correctly. The split decision is decided by the Group
Optimizer, which is a non-trivial module but maybe not as complex as you
thought.
zu 4)
We do have a implementation of NiagaraCQ. You should be able to get the
code along with the other part from the web. CQ also uses the same GUI with the
query engine system.
Hope I have answered all your questions,
Jianjun
Chen
2
Mailkorrespondenz XFilter:
·
Meine Anfrage, 04.06.2001:
Hello,
my name is Michael Stollberg and I would like to address you with some
questions on your projects / papers of the DBIS Toolkit and especially the
XFilter-System. The purpose of these questions is that I'm a student of
computer science at the "Freie Universität Berlin", Berlin, Germany -
and as a studies' work I'm comparing different approaches on Information
Systems which match user profiles against data hold in XML format for large
scale environments (the Internet). Actually two systems are on focus: your
XFilter-System and the NiagaraCQ-Approach (which you did critize as
not-scalable because of inefficient filtering :)).
My questions concern two topics: first (and most important) detailed
questions on the XFilter-System and secondly some more general information on
the DBIS Toolkit - I would be very glad if you could help me finding a
sufficient answer.
XFilter:
1) I would like to start with the most
complex question: it is about the possible quality of a profile declaration on
the XFilter System. The important aspects are:
a) Which kind of Query can I define in a profile?
b) Is XFilter able to join information from different
data sources and notify the user with the result as a combined information?
Let me give you an example: I (as the User) want to be
notified if stock quotes from CompanyA rises and the notification shall include
general information on CompanyA. Therefore we have two XML-Files (just
extracts):
quotes.xml: ..... <quote>
<company_name>CompanyA</company_name><amount>$
5.00</amount></quote> ....
companies.xml: ...<company><name>CompanyA</name><adress>...</adress></company>
....
Now the quotes.xml is updated and the CompanyA has:
<amount>$ 6.00</amount>.
How does the XPath - Query of my Profile look like? a
proposal: contains ((//company/name), (//quote [amount>quote_old/amount]/company_name)).
Is a profile declaration like this possible (although the XPath Syntax might be
wrong..)?
Or can I only declare a profile like this:
"Please send me every XML-Document which contains a structure like
'//quote/amount' " ?
In
chapter 4.1 of the XFilter-Paper (Efficient Filtering of XML-Documents for SDI)
you say that the system is able to deal with boolean-combination profiles which
is handled in the Profile Base after the Query-Index-Filtering. Does this
queries like the example above are handable or does the Profile Base- Component
have another functionality?
2) Secondly I would like to know if there is any
implementation available so I can have a look on the System. Maybe it is
possible that I can define a profile myself on some URL?
DBIS Toolkit
1) Am I right to say that the DBIS Toolkit describes a
framework of how Information Dissemination Systems should work by defining the
components and their tasks of such a system?
2) And may I also be right to say that the XFilter is
an implementation of the DBIS Toolkit Framework?
3) All the papers I have read from the DBIS project
side are at least 2 years old. Does this mean that the DBIS Toolkit Project is
finished or not updated anymore?
I hope you might be able to give me some kind of answer - especially the first question would be of importance. I know that I might pointed out a lack of the XFilter-System (if it is not possible to handle such kind of queries the system would just work as a delivering system (e.g. for a personalizable web news paper) but not on a high quality information system!) and I hope you do not feel attacked personally. Well, I also could be wrong with this assumption and I would be pleased if you could put me on the right track.
I thank you for taking so much time to read this upto this point and I would be glad receiving an answer.
Greetings from
Germany
MICHAEL STOLLBERG
·
Antworten 05. / 07.06.2001:
Hi Michael,
Thanks for your questions and your interest in
DBIS/XFilter. I'll take a quick try at your questions and Mehmet can add his comments or correct what I get
wrong.
In terms of the question of profile power, the current
XFilter only processes one XML document at a time. That means that joins across multiple documents are not
supported. If a single document contains the stock price and the other
information, then it would be possible to write an Xpath query and such a query
could be handled by XFilter (using a boolean combination of the two queries –
implemented by the profile base.)
A direction for future work in XFilter is to extend it
to a more powerful language (such as XQuery) and to allow it to process
multiple documents. This latter issue
changes the system significantly.
In terms of an implementation --- we haven't been
releasing this generally, but we may be able to give you a copy (but with no
support, of course). I'm traveling now,
please send me a reminder after June 12 when I will be back in Berkeley.
In terms of the relationship between DBIS and XFilter,
you are right that DBIS is a type of framework. A key part of this frame work is a profile language and engine,
and XFilter is an example of one of these.
We have not been working on DBIS much recently, but
Stan Zdonik and I (with Mitch Cherniack) have a follow-on project called
"data centers", which I can send you a paper about when I get back.
Hope this helps,
Mike Franklin
Hi Michael,
I have just a few things to add to Mike's comments. In
XFilter, user profiles contain pure XPath queries. That means, the power of
XFilter profile model is bounded with the power of XPath language. So, the
profile model is very powerful in processing single XML documents one at a time
but it does not support joins accross multiple documents.
XFilter supports structure and content matching for a
single document. With the help of Profile Base component, you can combine
multiple XPath queries in a single profile. After each XPath query is executed
independently (Note that they are executed on the same document!), the Profile
Base takes care of finding the final result for the profile. Please note that
this result is a boolean value, i.e. success or fail.
You might want to check out another work that extends
XFilter model considering mobile environments: http://www.srdc.metu.edu.tr/papers/cqmc_longVersion.pdf
As for the DBIS Toolkit work, I think Mike explained
current status well.
Thanks again for your interest for DBIS
Toolkit/XFilter
and good luck in your studies.
Mehmet